
Getting To Know the Linux Filesystem
The Unix / Linux filesystem hierarchy can seem quite daunting to those new to the OS. It was the same for us when we got started. But this mysterious filesystem isn’t that mysterious after all; we just need some explanation to go along with the directory names.
Linux is a great operating system. It runs on everything from a single-board system to a super computer. But for those users moving from a Windows environment, the filesystem can be daunting. Linux is gaining popularity for gaming, largely down to the Steam Deck. But it is computers such as the Raspberry Pi which are introducing Linux to a new generation.
A typical Linux filesystem
So let’s take a look at a typical Linux filesystem found in a modern day install. We’re using Kubuntu 22.04 but the directory structure will be the same for a Raspberry Pi and a data center.
| / | The root directory from where all other directories are available from. |
| bin | Essential commands (binaries) necessary for the system are kept here. |
| boot | Boot loader files (kernel, grub, initrd). |
| dev | Links to device files (hard drives, USB devices). |
| etc | Host specific configuration files. |
| home | Home directory for users. |
| lib | Libraries for the binaries |
| lost+found | Contains files that have been deleted or lost in a disk operation. |
| media | Mount points for removable media (CD / DVD / USB) |
| mnt | Temporary mount point |
| opt | Add-on application software packages |
| proc | Virtual filesystem for processes and kernel. |
| root | Home directory for the root user |
| run | Run-time variable data. Information about the running system since last boot. |
| sbin | Essential system binaries. |
| srv | Specific data for web / FTP servers. |
| sys | Contains device, drivers and kernel information. |
| tmp | Temporary files are stored here. |
| usr | Contains commands and applications for all users. Secondary hierarchy, read only access. |
| var | Variable files, files that are expected to often change. For example, log files. |
Got root?
The starting point for the UNIX filesystem is the root directory, often referred to as /. This is the start for every directory on our system and typically only root, or a user in the sudo group will be able to write anything to this directory. The majority of files (if any) in this directory are read only to other users. The root user has its own home directory, which is where files and directories necessary for their work can be found.
From the root directory we move on to bin, short for binaries. In this directory we can find the absolute essential commands. We can spot commands such as cat, grep, ls, less etc. This directory is typically kept as is; we don’t want to install our break any files located here as it could render our system unusable.
Binaries, Applications and Utilities
The filesystem has many locations for commands and applications.
For critical commands and utilities we have bin. This directory contains many of the commands that we use at the terminal, ls, cp, mv. In our Ubuntu desktop we have 2453 binaries in this directory alone! The bin directory has everything that we need to have a usable Linux environment. The directory also contains the tools that we need to maintain the system, including the tools necessary when running in single user mode (a mode where a single superuser maintains the installation). As such, we largely leave bin alone as an incorrect keypress could bring a system down.
Another location for commands is sbin and this is where the absolutely essential commands are located. The “S” in sbin refers to “superuser”, a root user or a user with sudo privileges. These commands are only for privileged users and the directory contains tools to work with filesystems, networking and background services.
What if we want to use our own applications in the terminal? Can we just drop them into bin or sbin? The answer is no. Those directories should be left as is. Our applications should reside in /usr/local/bin or /usr/bin/ so that they do not interfere with any other directories. Another location to store our own applications is /opt/. Relatively few applications use this directory. On our test machine we found directories for Google Chrome, Balena’s Etcher, and Zoom.
The Mysterious Directories
There are quite a few directories that can leave the Linux newcomer wondering “What does this directory do?” First on this hallowed list is etc. Pronounced “et-see”, the etc directory contains configuration files specific for your machine. Here we find configuration files for the Common Unix Print Service (cups), sensors (temperature) and cron (scheduling commands to run at set times).
The dev directory is where devices are located. Linux treats everything as a file, including physical devices and this directory is where we can find them. Devices such as disks, inputs and serial consoles (/dev/tty) reside here. In our experience we have used this directory to locate USB to Serial interfaces for devices such as Raspberry Pi Pico and other microcontrollers.
lib
Short for libraries, lib is where we can find libraries essential to running the system. Here we can find kernel libraries and other essential files for our system. The libraries work in a similar manner to Windows DLL files.
A mysteriously named directory, “lost+found” sounds more at home at a bus terminal. But this directory is where obsolete/incomplete data is kept. If we ever need to reconstruct data, after an unscheduled power loss, error or bug, then we would use fsck along with lost+found.
proc
Short for Processes, proc is a mount point for the proc filesystem. This entire directory contains files that show information on the current running processes. Each process is numbered, a PID, that we can identify by running a command such as top, htop, ps or bpytop. We used top to identify our Chrome browser process, then used the PID to change directory into the process. Using the proc directory we can explore the running processes, examine them for issues, information and extract data from running processes.
The run directory contains information about the system since it was booted. Any commands, be they automatic or started by the user, will leave a trace here. For example, when writing this feature we used peek to record part of our screen. In the run directory we found the relevant subdirectory containing the apps data.
Typically used for site-specific data, srv is used to store data files for a particular service. If you are serving web pages, CGI scripts can be used from this directory. On our test system, this directory is empty as we do not run any web services.
sys
Working in a similar manner to proc, sys is a directory that stores information about the kernel. Structured into a series of directories for system buses, devices, firmware etc, it is easier to work with that finding raw PIDs as we did with proc.
Inside the tmp directory are a collection of temporary files and directories. These files and directories can be deleted with no notice, so ensure that you only use this directory for data that you no longer need. One trick with tmp is when we download installation files, saving these to tmp and running the installation means we don’t have to worry about cleaning up the installation files after use.
So what does usr contain? Well, usr is one of the most important directories in the Linux filesystem. In here we find all of the user-land (code that runs outside of the kernel) resides. The /usr/bin/ subdirectory contains many commands that we use on a daily basis. Further subdirectories contain libraries for user-land applications (/usr/lib), shared files such as fonts and icons (/usr/share) and Linux kernel source files contained in /usr/src/.
var
Our final mysteriously named directory is var. This directory is where files which may regularly change in size. Webmasters will be familiar with this directory as it is common to serve a website using /var/www/. The var directory is also the home of log files (/var/log). If something goes wrong, this is the directory to look into. We can examine the kernel logs, syslogs and the dpkg log, used to log the details of installing applications using dpkg or apt. In fact, apt has its own subdirectory, /var/log/apt, which contains term.log and history.log. These files show the applications installed using apt. We spotted two applications that we installed for this feature: tree, which we used to map the hierarchy, and pv which we used to slow down the output of listing the contents of the bin directory.
There’s no place like home (directory)
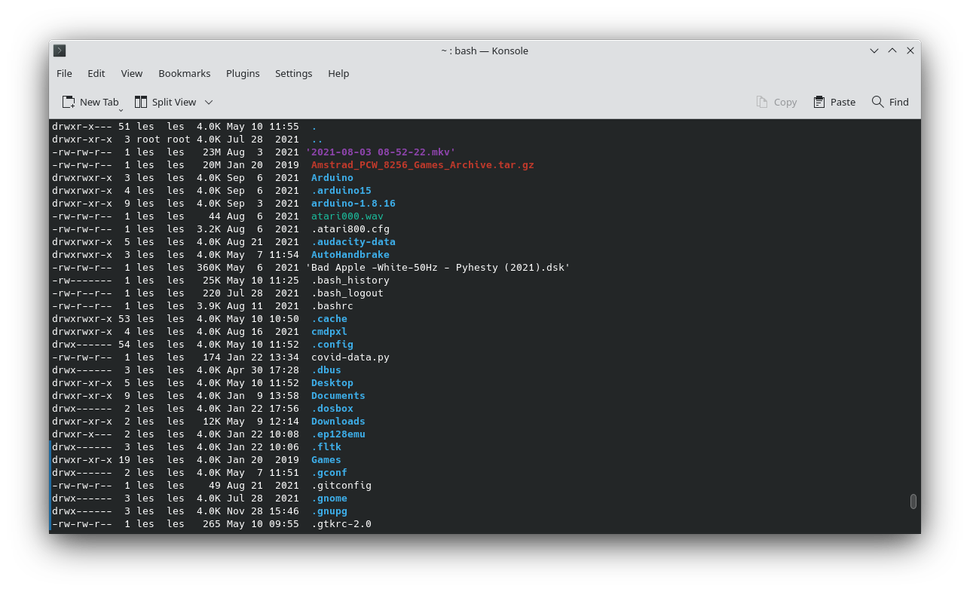
Each user has their own home directory. A space where they can store their documents, work, videos etc. Typically users will only use their home directory, never straying into the main filesystem. Should an application require a user specific configuration, it will save to one of a few hidden directories. Directories which start with a “.” are hidden from general view, but we can see them using the ls command along with three arguments. The first is -l and this ensures the data is displayed as a list. Next is -h, which formats the data using values a human would easily understand (2048MB becomes 2GB etc). Finally the -a argument shows all the files, even the hidden files.
ls -lha
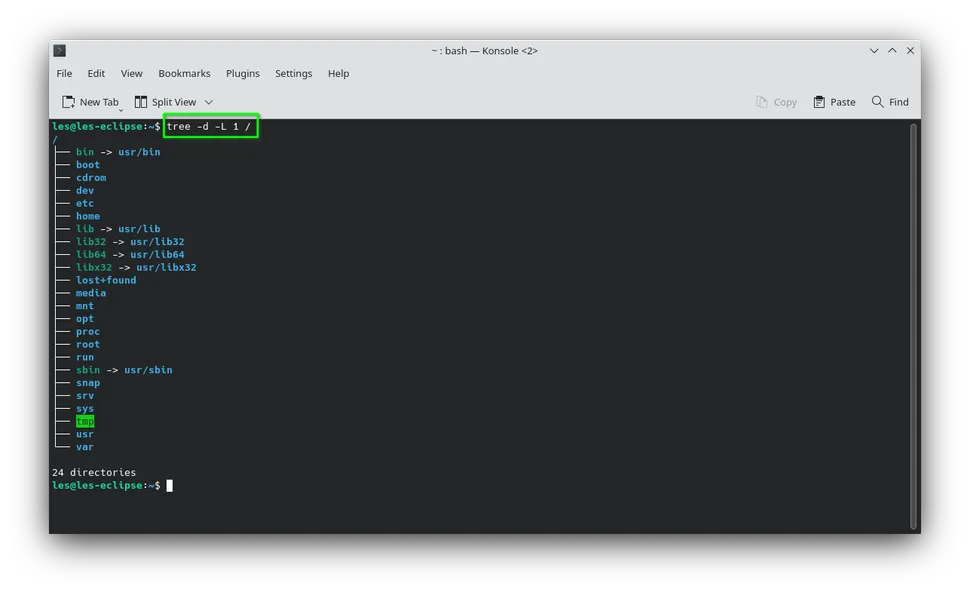
To get a view of your Linux filesystem hierarchy use the tree command. As you can guess, the tree command lists the contents of filesystems in a tree-like structure.
1. Open a terminal, and update your software repositories.
sudo apt update
2. Install tree using the apt package manager.
sudo apt install tree
3. Use tree to view the structure of your Linux filesystem. We will limit the output to just one level (-L 1) and only directories (-d) and set the start point to be our root /.
tree -d -L 1
Read more: https://www.tomshardware.com/how-to/getting-to-know-the-linux-filesystem


